

The idea of machine translation may be traced back to the 17th century. In 1629, René Descartes proposed a universal language, with equivalent ideas in different tongues sharing one symbol. The field of “machine translation” appeared in Warren Weaver‘s Memorandum on Translation (1949). The first researcher in the field, Yehosha Bar-Hillel, began his research at MIT (1951). A Georgetown University MT research team followed (1951) with a public demonstration of its Georgetown-IBM experiment system in 1954.
MT research programs popped up in Japan and Russia (1955), and the first MT conference was held in London (1956). Researchers continued to join the field as the Association for Machine Translation and Computational Linguistics was formed in the U.S. (1962) and the National Academy of Sciences formed the Automatic Language Processing Advisory Committee (ALPAC) to study MT (1964).
Real progress was much slower, however, and after the ALPAC report (1966), which found that the ten-year-long research had failed to fulfill expectations, funding was greatly reduced.
Early machine translations (as of 1962 at least) were notorious for thier mistranslations as they simply employed a database of words.
Later attempts utilized common phrases which resulted in better grammatical structure and capture of idioms but with many words left in the original language. The best systems today use a combination of the above technologies and apply algorithms to correct the “natural” sound of the translation.
Literal translation of idioms is a source of numerous translators’ jokes and apocrypha. The following famous example has often been told both in the context of early translators and that of machine translation: When the sentence “The spirit is willing, but the flesh is weak” (дух бодр, плоть же немощна, an allusion to Mark 14:38) was translated into Russian and then back to English, the result was “The vodka is good, but the meat is rotten” (водка хорошая, но мясо протухло).
This is generally believed to be simply an amusing story, and not a factual reference to an actual machine translation error, so we tried this on the much more advanced Google Translate. The latter auto-detected the (claimed to be Russian) idiom as Belarusian.

It would seem current state of the art machine translation has overcome the early translators idiom problem, and the story is indeed an urban legend. But as the original tale mentioned Russian to English (Belarus regained its independent status in 1991), we thought it may be interesting to force the translator to consider the Cyrillic idiom as Russian rather than Belarusian.
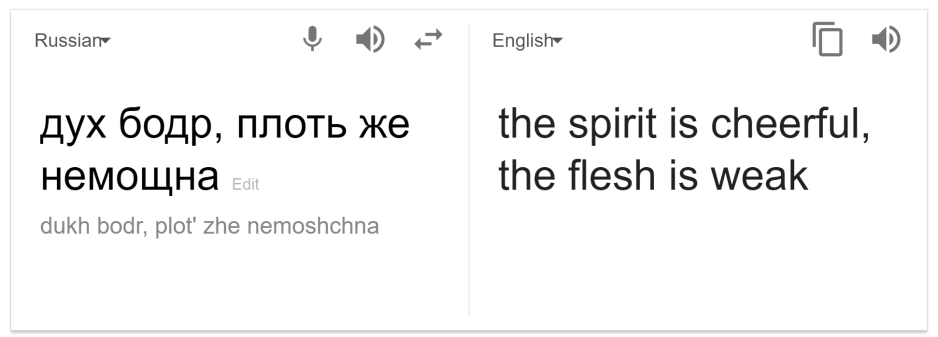
Seems we have easily fooled the machine into a slight mistranslation (cheerful instead of willing). That may be due to subtle distinctions between the two dialects, and how the translator was trained (possibly fitted to the Belarusian dialect over the Russian one). However, what about the original English-to-Russian-and-back-to-English approach.
We tried that too with results somewhat supporting the original tale.
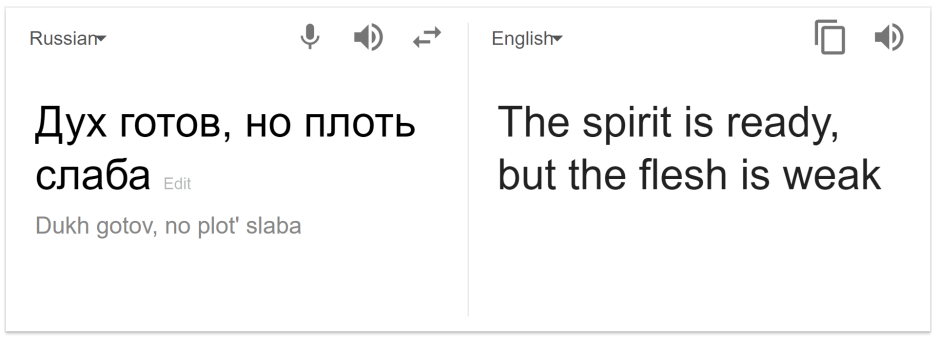
That is not to say that machine translation has not gone an extremely long way than the early systems of the 50s and early 60s. It has. The methods employed have greatly improved, but the deeper question remains. Can computers ever truly understand language.
John Searle, an American philosopher, suggested a gedankenexperiment known as The Chinese Room (1980).
In his experiment Searle tries to give a compelling argument supporting his claim that computers, no matter how advanced, would never be able to understand language the way humans do.
Searle’s 1980s thought-experiment begins with this hypothetical premise: suppose that artificial intelligence research has succeeded in constructing a computer that behaves as if it understands Chinese. It takes Chinese characters as input and, by following the instructions of a computer program, produces other Chinese characters, which it presents as output. Suppose, says Searle, that this computer performs its task so convincingly that it comfortably passes the Turing test: it convinces a human Chinese speaker that the program is itself a live Chinese speaker. To all of the questions that the person asks, it makes appropriate responses, such that any Chinese speaker would be convinced that they are talking to another Chinese-speaking human being.
The question Searle wants to answer is this: does the machine literally understand Chinese? Or is it merely simulating the ability to understand Chinese?
Searle then supposes that he is in a closed room and has a book with an English version of the computer program, along with sufficient paper, pencils, erasers, and filing cabinets (it was 1980 after all). Searle could then receive Chinese characters through a slot in the door, process them according to the program’s instructions, and produce Chinese characters as output. If the computer had passed the Turing test this way, it follows, says Searle, that he would do so as well, simply by running the program manually.
He then asserts that there is no essential difference between the roles of the computer and himself in the experiment. Each simply follows a program, step-by-step, producing a behavior which is then interpreted as demonstrating intelligent conversation. However, Searle would not be able to understand the conversation. (“I don’t speak a word of Chinese”, he points out.) Therefore, he argues, it follows that the computer would not be able to understand the conversation either.
The Chinese Room experiment is considered the most discussed philosophical paper in the last decades and has received numerous rebuttals. Searle still holds his ground (even tough in his book “Mind” (2004), he tends to soften his original argument), but the question remains.
As we cannot present the entire set of philosophical argumentation rebutting the Chinese Room here, let me suggest a simple question that points out the main flaw in the argument.
In the heart of Searle’s claim, as he openly admits, lies the subjective feeling of understanding of the meaning of words and phrases, as opposed to mechanically interchanging one for the other.
Searle cleverly asks you to test whether you feel that your (his) understanding of language is replicated within a mechanical (electrical) instrument crunching numbers and outputting a (correct) result.
By doing so he encourages the reader to further put himself in Searle’s shoes (sitting in that room), suggesting that the reader also does not know Chinese, therefor a computer performing the same tasks does not either.
It’s a rhetorical trick.
Try substituting the word room with person. The fact of the matter is that you have no way of knowing whether the person you are talking to truly understands the meaning of your words, apart from your subjective feeling he does, and the fact that the person responses (as does the room’s) seem appropriate. Sounds familiar? This is Searle’s main claim regarding the room itself.
But Searle is not completely off.
Reading machine translated texts, as good as they may be, one can often point out the tiny inarticulations produced by the machine. Without going into the deeper question of understanding, intentionality and consciousness, it seems current efforts would not yet pass the Turing test in the general case. A vivid example of where machine translation poorly fails is poetry.
The thing about poetry is that it is a culmination of language. A tightly coupled mixture of words’ and phrases’ meanings, idioms, hidden semantic layers, words that are taken out of their original semantic role overloaded with new meanings in new contexts, rhyme, morphological and textual novel structures, word fusing and phrases that are syntactically well-formed but are rarely or never used by regular speakers.
Take this example. Cesar Vallejo, a renowned Peruvian poet, who is well known for his poetic masterpiece Trilce (Spanish, 1922), has produced poems that baffle even the most articulate human translators.
Translating Trilce is a monumental task as Vallejo’s language is complex and ridden with intricate lexical structures and overloaded meanings. Naturally, we fed one his Trilce poems into Google Translate.
Trilce, XXXIV // Cesar Vallejo
| Human Translation (from Spanish) | Google Translate (from Spanish) |
Finished the stranger, with whom, late at night, you returned to words for words. Now there won’t be anyone who waits for me, readies my place, good itself ill. Finished the heated afternoon; your great bay and your clamor; the chat with your exhausted mother who offered us a tea full of evening. Finally finished everything: the vacations, your obedience of hearts, your way of demanding that I not go out. And finished the diminutive, on behalf of my majority in the endless ache and our having been born like this for no cause. |
The stranger is over, with whom, later At night, you came back and talked. There will be no one to wait for me, willing my place, good the bad. The hot afternoon is over; your great bay and your cry; the talk with your mother finished that gave us a tea full afternoon. It's all over at last: the holidays, your obedience of breasts, your way to ask me not to go away. And the diminutive is over, for my majority in endless pain, and our being born that way without cause. |
You don’t have to read Spanish, nor be an expert on Vallejo to immediately see the difference. The human translation looks right, while the machine translation looks as if a seven year old has done some low level literal translation of the original.
Why?
What is the basic algorithmic flaw that prevents the mechanical translator from capturing the meaning, rhyme and deeper textual relationships within Vallejo’s masterpiece?
The answer, as Inigo Montoya told Vizzini in the Princess Bride: “You keep using that word. I do not think it means what you think it means.”. Translating poetry is not what you think it [translation] is.
Would computers ever be able to translate poetry? On this, in detail, on the next edition of the Lazarus.
